
# 🔦 Highlights
share an IPFS node between multiple tabs and pin files more quickly
js-IPFS@0.50.0 has landed with the ability to share a node between multiple browser tabs and greatly improved pinning performance.
We're also phasing out use of Node.js Buffers as data types in favour of standard JavaScript Uint8Arrays.
Read on for the full details!
# 🤝 Share a node between browser tabs
An IPFS node makes lots of connections to other nodes on the network, and more so since delegate nodes were turned on by default (opens new window). This is to ensure you have the greatest chance of finding content on the network, and so other people have the greatest chance of finding your content on the network.
This does not come without a price though, maintaining multiple connections can be resource-intensive and in some cases the browser will limit the number of concurrent connections you can have have.
This can be a problem in web browsers if the user opens your app in two tabs, suddenly you have two nodes running with twice the number of open connections. Worse, they are sharing a datastore and the same peer ID.
Help is at hand in the shape of the ipfs-message-port-client (opens new window) and ipfs-message-port-server (opens new window) which allow you to run one IPFS node in a SharedWorker (opens new window) and share it between multiple tabs within your application.
There will be a more in depth post here on this subject soon but in the meantime check out the browser-sharing-node-across-tabs (opens new window) example to see how to use it!
# 📌 Pinning performance
When you add a piece of content to your local IPFS node, it's pinned in place to prevent the blocks that make up your files being deleted during garbage collection. The pin is placed in a collection of pins we call a pinset.
The datastructure behind this pinset is a DAG (opens new window), much like the structures that represent the files and folders you'd added to IPFS. The root CID (opens new window) of the DAG (opens new window) is stored in the datastore and all the blocks that make up the DAG (opens new window) are stored in the blockstore.
The pinset consists of a number of buckets in a tree structure, with each bucket containing a max of 8,192 items and each layer containing max 256 buckets. After the first bucket is full, pins are distributed between buckets.
When garbage collection runs, all nodes in the DAG (opens new window) are traversed and the blocks that correspond to their CID (opens new window)s are exempted from deletion.
As you add and remove pins, this DAG grows and shrinks. CID (opens new window)s of intermediate nodes within the DAG (opens new window) are recalculated as the structure changes. As the DAG (opens new window) gets larger this can become expensive and it hurts application performance for very large pinsets.
js-ipfs@0.50.0 has changed the default storage of pins to use the datastore instead of a DAG (opens new window) and has seen a corresponding speedup as the number of pinned blocks in your repo increases:
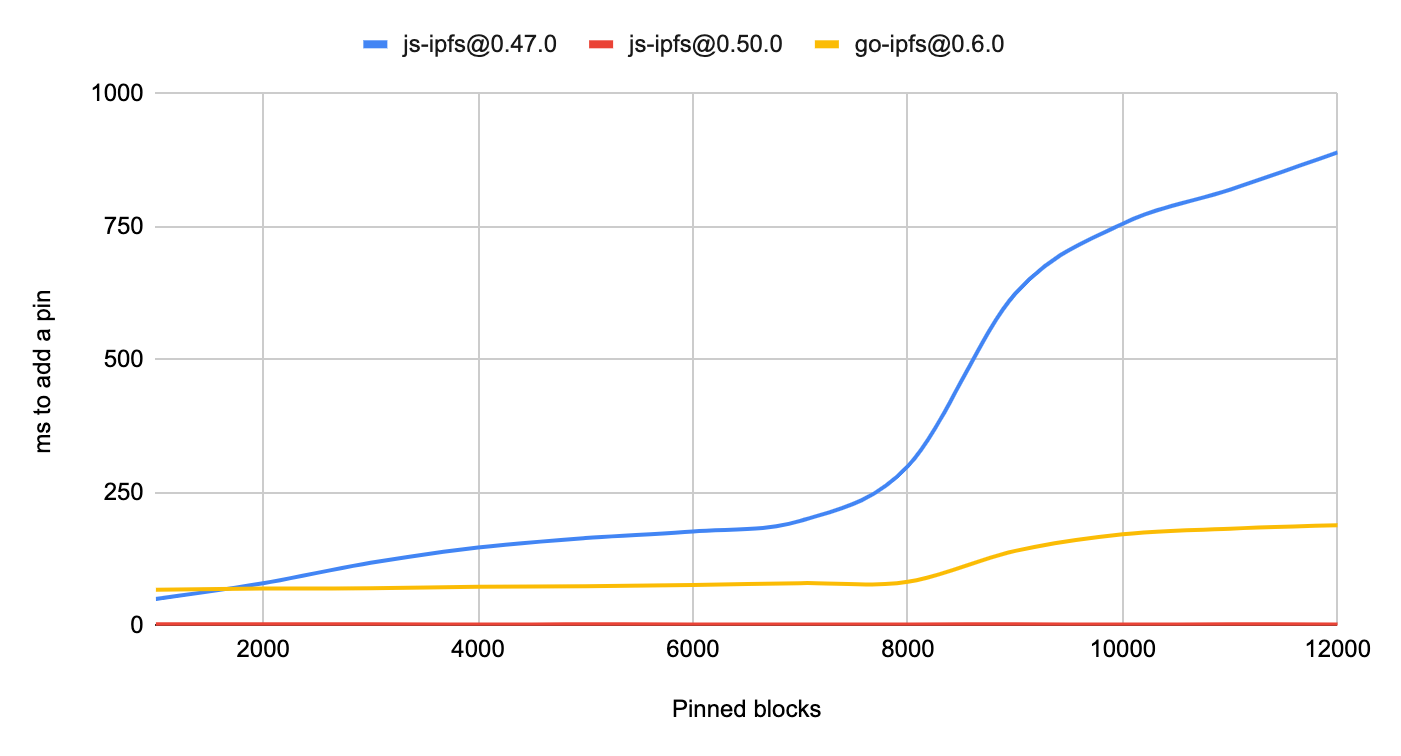
In the diagram above you can see that as the number of pinned items increases, so does the time it takes to add the next pin. There's a steep increase at 8,192 pins, which is when the first bucket is considered full and multiple buckets are created which then involves more operations to add the next pin.
The performance of the approach taken by js-ipfs@0.50.0 compares very favourably to that of previous versions and is essentially only limited by the peformance of the underlying datastore since it has switched to simple puts and gets without the overhead of creating a data structure.
# 🍫 Uint8Arrays
In the beginning there were Arrays. Simple arrays that could hold all sorts of mixed types, could not be optimised very well and were an abstraction over blocks of memory.
Then Node.js came along and introduced the Buffer (opens new window) - suddenly JavaScript developers could access memory (sort of) directly! These things held numbers with an integer value range of 0-255 and were blazingly fast. JavaScript was starting to look like a proper language that you could do resource intensive work in.
The authors of the ECMAScript (opens new window) standard took note and introduced TypedArray (opens new window)s, of which there are many variations but the one we are most interested in is the Uint8Array (opens new window).
These types of arrays hold numbers with an integer value range of 0-255 and support an API very similar to that of Node.js Buffers, which should come as no surprise as since v3.0.0 of Node.js, Buffers have been a subclass of Uint8Arrays.
These are exciting times so going forwards as JavaScript becomes more capable and the browser support arrives we are reducing our dependence on core Node.js libraries and utilities. Part of that is removing all use of Node.js Buffers in our codebase.
With js-ipfs@0.50.0 you should stop relying on Node.js Buffers to be returned from any part of the Core-API (opens new window), instead you should code against the Uint8Array interface.
Some modules that we depend on will still return Buffers, which we pass on to avoid any conversion cost but we hope to remove or refactor these over time. In order to remain forwards-compatible you should not use Node.js Buffer methods on any of these returned values.
For example in the code below we create a Buffer from the string 'Hello', add it to IPFS then immediately cat it and call toString() on the chunks. This takes advantage of the fact that the Buffer we've added is utf8 encoded. Buffer.toString() takes an encoding argument which is utf8 by default, so the below code works but it's only by coincidence:
const { cid } = await ipfs.add(Buffer.from('Hello'))
for await (const chunk of ipfs.cat(cid)) {
console.info(chunk.toString()) // prints 'Hello'
}
Instead we would use the TextEncoder (opens new window) and TextDecoder (opens new window) classes. These are explicit in the encoding/decoding they use (also utf8 by default) so are safer to use:
const encoder = new TextEncoder()
const decoder = new TextDecoder()
const { cid } = await ipfs.add(encoder.encode('Hello'))
for await (const chunk of ipfs.cat(cid)) {
console.info(decoder.decode(chunk)) // prints 'Hello'
}
# ✨New features
- Store pins in datastore instead of a DAG (#2771 (opens new window)) (64b7fe4 (opens new window))
- Add protocol list to ipfs id output (#3250 (opens new window)) (1b6cf60 (opens new window))
- IPNS publish in browser example (#3207 (opens new window)) (91faec6 (opens new window))
- Update hapi to v20 (#3245 (opens new window)) (1aeef89 (opens new window))
- Update to libp2p@0.29.0 (63d4d35 (opens new window))
# 🔨 Breaking changes
- Node Buffers have been replaced with Uint8Arrays (#3220 (opens new window))
# 🏗 API Changes
# Core API & HTTP API Client
- The return value from
ipfs.idnow includes a list of protocols the node understands - 💥 Breaking Change 💥 Where Node.js
Bufferobjects were returned previously, nowUint8Arraysare in their place. This affects:ipfs.block.*The.dataproperty of block objects is now aUint8Arrayipfs.dag.getDepending on the type of node returned:ipld-rawnodes are now returned asUint8Arrays- The
.dataproperty of returnedipld-dag-pbnodes is now aUint8Array
ipfs.dht.getReturns aUint8Arrayipfs.catFile data is now returned asUint8Arraysipfs.files.readFile data is now returned asUint8Arraysipfs.object.dataObject data is now returned as aUint8Arrayipfs.pubsub.subscriptData published to a topic is now received as aUint8Array
For further reading, see the Core API Docs (opens new window).
# 🗺️ What’s next?
Check out the js-IPFS Project Roadmap (opens new window) which contains headline features organised in the order we hope them to land.
Only large features are called out in the roadmap, expect lots of small bugfix releases between the roadmapped items!
# 😍 Huge thank you to everyone that made this release possible
- @abbasogaji (opens new window) (1 issue, 1 comment)
- @achingbrain (opens new window) (77 commits, 33 PRs, 1 issue, 57 comments)
- @alanshaw (opens new window) (3 commits)
- @aphelionz (opens new window) (1 issue, 3 comments)
- @aschmahmann (opens new window) (1 comment)
- @AuHau (opens new window) (1 commit, 1 PR, 2 issues, 5 comments)
- @bluelovers (opens new window) (1 PR, 2 issues, 4 comments)
- @bmann (opens new window) (1 issue, 1 comment)
- @christopheSeeka (opens new window) (1 comment)
- @codecov-commenter (opens new window) (15 comments)
- @crypt0maniak (opens new window) (1 PR, 2 comments)
- @dave-dm (opens new window) (1 issue)
- @dependabot[bot] (opens new window) (2 commits)
- @duxiaofeng-github (opens new window) (1 issue)
- @er123rin (opens new window) (1 PR)
- @ffa500 (opens new window) (1 comment)
- @Gozala (opens new window) (1 commit, 1 PR, 1 issue, 21 comments)
- @hugomrdias (opens new window) (2 commits, 1 comment)
- @hunterInt (opens new window) (1 issue)
- @icidasset (opens new window) (1 comment)
- @jacekv (opens new window) (1 issue, 1 comment)
- @jacobheun (opens new window) (23 commits, 6 PRs, 1 issue, 28 comments)
- @josselinchevalay (opens new window) (1 issue, 2 comments)
- @koivunej (opens new window) (2 issues, 1 comment)
- @lidel (opens new window) (2 comments)
- @lukaw3d (opens new window) (1 issue, 1 comment)
- @mikeal (opens new window) (1 commit)
- @mitjat (opens new window) (1 comment)
- @moodysalem (opens new window) (1 issue, 5 comments)
- @mrh42 (opens new window) (1 issue)
- @negamaxi (opens new window) (1 issue, 1 comment)
- @olivier-nerot (opens new window) (1 issue, 1 comment)
- @olizilla (opens new window) (2 commits, 1 PR, 1 comment)
- @onichandame (opens new window) (1 comment)
- @OR13 (opens new window) (2 issues)
- @rvagg (opens new window) (5 comments)
- @shazow (opens new window) (1 commit, 1 PR)
- @StationedInTheField (opens new window) (1 issue, 4 comments)
- @tabcat (opens new window) (1 PR, 2 issues, 4 comments)
- @Tcll (opens new window) (2 issues, 4 comments)
- @tk26 (opens new window) (1 commit, 1 PR, 3 comments)
- @vasco-santos (opens new window) (66 commits, 20 PRs, 3 issues, 24 comments)
- @vmx (opens new window) (2 commits, 1 PR, 3 comments)
- @vojtechsimetka (opens new window) (1 commit, 1 PR)
- @welcome (11 comments)
- @wemeetagain (opens new window) (35 commits, 6 PRs, 2 issues, 5 comments)
- @Xmader (opens new window) (3 commits, 3 PRs, 2 comments)
- @xmaysonnave (opens new window) (1 issue, 1 comment)
# 🙌🏽 Want to contribute?
Would you like to contribute to the IPFS project and don’t know how? Well, there are a few places you can get started:
- Check the issues with the
help wantedlabel in the js-IPFS repo (opens new window) - Join an IPFS All Hands, introduce yourself and let us know where you would like to contribute: https://github.com/ipfs/team-mgmt/#weekly-ipfs-all-hands
- Hack with IPFS and show us what you made! The All Hands call is also the perfect venue for demos, join in and show us what you built
- Join the discussion at https://discuss.ipfs.tech/ and help users finding their answers.
- Join the 🚀 IPFS Core Implementations Weekly Sync 🛰 (opens new window) and be part of the action!
# ⁉️ Do you have questions?
The best place to ask your questions about IPFS, how it works, and what you can do with it is at discuss.ipfs.tech (opens new window). We are also available at the #ipfs channel on Freenode.